Data Analysis
2D-Gel Statistics
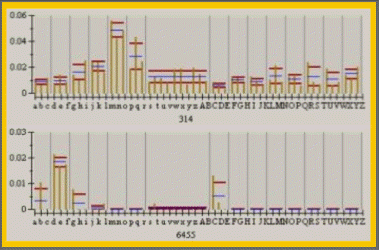
Histogram data of spot groups no. 314 & 6455 from WITA-Proteomics AG Hep-G2 database1
Each vertical bar (dark yellow lines) stands for the relative spot volume representing the group within the respective gel. Means (blue lines) and standard deviation (red lines) are calculated for all treatment classes. The largest class (10 gels, above group no.) represents the control group.
(Courtesy of Eurogentec SA, Seraing, Belgium)
In project designs like target finding or mode of action studies, the intermediate goal on the way towards the identification of differentially expressed proteins is to obtain a high quality i.e. statistically sound 2D-gel database.
Typically, the %Vol of individual classes can be reproduced within +/-30%, assuming that three replicate gels have been used per class. Sporadic outliers can be observed due to the remaining spot matching errors. However, at this level of database editing, outliers are easily spotted - even by the inexperienced eye.
Higher statistic rigor can be achieved by increasing the number of gels evaluated per class. Judging from the statistical view point, a minimum number of ten gels per class would pose a proper data set. However, a number of 3-5 gels per class is usually chosen by most researchers due to bugdet or time constraints.
1Thome-Kromer B, Bonk I, Klatt M, Nebrich G, Taufmann M, Bryant S, Wacker U and Köpke A.
TOWARD THE IDENTIFICATION OF LIVER TOXICITY MARKERS: A PROTEOME STUDY IN HUMAN CELL CULTURE AND RATS. Proteomics 2003; 3(10), 1835-62